ivy.trace_graph()#
⚠️ Warning: The tracer and the transpiler are not publicly available yet, so certain parts of this doc won’t work as expected as of now!
When we call an Ivy function, there is always a small performance hit due to added Python wrapping. This overhead becomes increasingly noticeable when we use large models with multiple function calls. The Tracer improves the performance of Ivy by removing the extra wrapping around each function call.
The Tracer takes in any Ivy function, framework-specific (backend) function, or composition of both, and produces a simplified executable computation graph composed of functions from the backend functional API only, which results in:
Simplified code: The Tracer simplifies the code by removing all the wrapping and functions that don’t contribute to the output: print statements, loggers, etc.
Improved performance: The created graph has no performance overhead due to Ivy’s function wrapping, likewise, redundant operations from the original function are also removed, increasing its overall performance.
Tracer API#
- ivy.trace_graph(*objs, stateful=None, arg_stateful_idxs=None, kwarg_stateful_idxs=None, to=None, include_generators=True, array_caching=True, return_backend_traced_fn=False, static_argnums=None, static_argnames=None, args=None, kwargs=None)#
Creates a
Callableor set of them into an Ivy graph. Ifargsorkwargsare specified, compilation is performed eagerly, otherwise, compilation will happen lazily.- Parameters:
objs (
Callable) – Callable(s) to trace and create a graph of.stateful (
Optional[List]) – List of instances to be considered stateful during the graph compilation.arg_stateful_idxs (
Optional[List]) – Positional arguments to be considered stateful during the graph compilation.kwarg_stateful_idxs (
Optional[List]) – Keyword arguments to be considered stateful during the graph compilation.to (
Optional[str]) – Backend that the graph will be traced to. If not specified, the current backend will be used.include_generators (
bool) – Include array creation/generation functions as part of the graph.array_caching (
bool) – Cache the constant arrays that appear as arguments to the functions in the graph.return_backend_traced_fn (
bool) – Whether to apply the native compilers, i.e. tf.function, after ivy’s compilation.static_argnums (
Optional[Union[int, Iterable[int]]]) – For jax’s jit compilation.static_argnames (
Optional[Union[str, Iterable[str]]]) – For jax’s jit compilation.args (
Optional[Tuple]) – Positional arguments for obj.kwargs (
Optional[dict]) – Keyword arguments for obj.
- Return type:
Union[Graph, LazyGraph, ivy.Module, ModuleType]- Returns:
A
Graphor a non-initializedLazyGraph. If the object is anivy.Module, the forward pass will be traced and the same module will be returned. If the object is aModuleType, the function will return a copy of the module with every method lazily traced.
Using the tracer#
To use the ivy.trace_graph() function, you need to pass a callable object and the corresponding inputs
to the function.
Let’s start with a simple function:
import ivy
ivy.set_backend("torch")
def fn(x, y):
z = x**y
print(z)
k = x * y
j = ivy.concat([x, z, y])
sum_j = ivy.sum(j)
return z
x = ivy.array([1, 2, 3])
y = ivy.array([2, 3, 4])
# Trace the function
traced_fn = ivy.trace_graph(fn, args=(x, y))
In this case, the created graph would be:
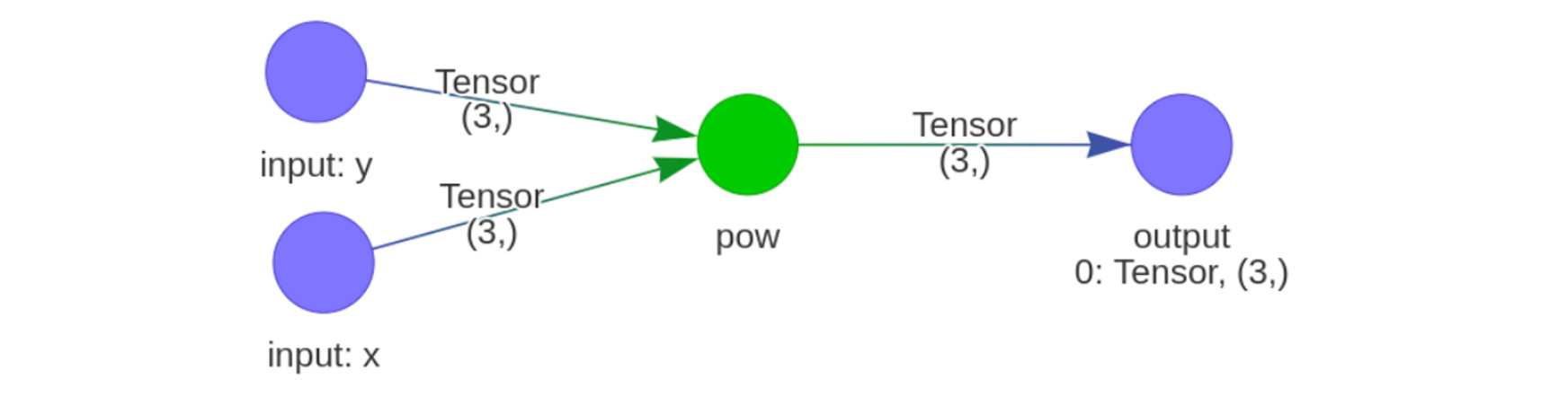
From the graph, we can observe that:
As
xandyare the only variables used when calculating the returned valuez, the non-contributing variable(s),kwas not included in the graph. Function calls that don’t contribute to the output like theprintfunction were also excluded.As we set the backend to
torchduring the compilation process, the traced functions are torch functions, and the input and output types are torch tensors.The tensor shape in the graph only indicates the shape of the inputs the graph was traced with. The tracer doesn’t impose additional restrictions on the shape or datatype of the input array(s).
# Original set of inputs
out = traced_fn(x, y)
# Inputs of different shape
a = ivy.array([[1., 2.]])
b = ivy.array([[2., 3.]])
# New set of inputs
out = traced_fn(a, b)
Eager vs lazy Compilation#
The Tracer runs the original function under the hood and tracks its computation to create the created graph. The eager compilation method traces the graph in the corresponding function call with the specified inputs before we use the traced function.
Instead of compiling functions before using them, Ivy also allows you to trace the
function dynamically. This can be done by passing only the function to the
trace method and not including the function arguments. In this case, the output will be a
LazyGraph instead of a Graph instance. When this LazyGraph object is first invoked with
function arguments, it Creates the function and returns the output of the traced
function. Once the graph has been initialized, calls to the LazyGraph object will
use the traced function to compute the outputs directly.
# Trace the function eagerly (compilation happens here)
eager_graph = ivy.trace_graph(fn, args=(x, y))
# Trace the function lazily (compilation does not happen here)
lazy_graph = ivy.trace_graph(fn)
# Trace and return the output
out = lazy_graph(x, y)
To sum up, lazy compilation enables you to delay the compilation process until you have the necessary inputs during execution. This is particularly useful in cases like compiling libraries, where it’s not feasible to provide valid arguments for every function call.
Now let’s look at additional functionalities that you can find in the tracer.
Array caching#
The tracer is able to cache constant arrays and their operations through the
array_caching flag, reducing computation time after compilation.
import ivy
ivy.set_backend("torch")
def fn(x):
b = ivy.array([2])
a = ivy.array([2])
z = x ** (a + b)
return z
comp_func = ivy.trace_graph(fn, args=(x,))
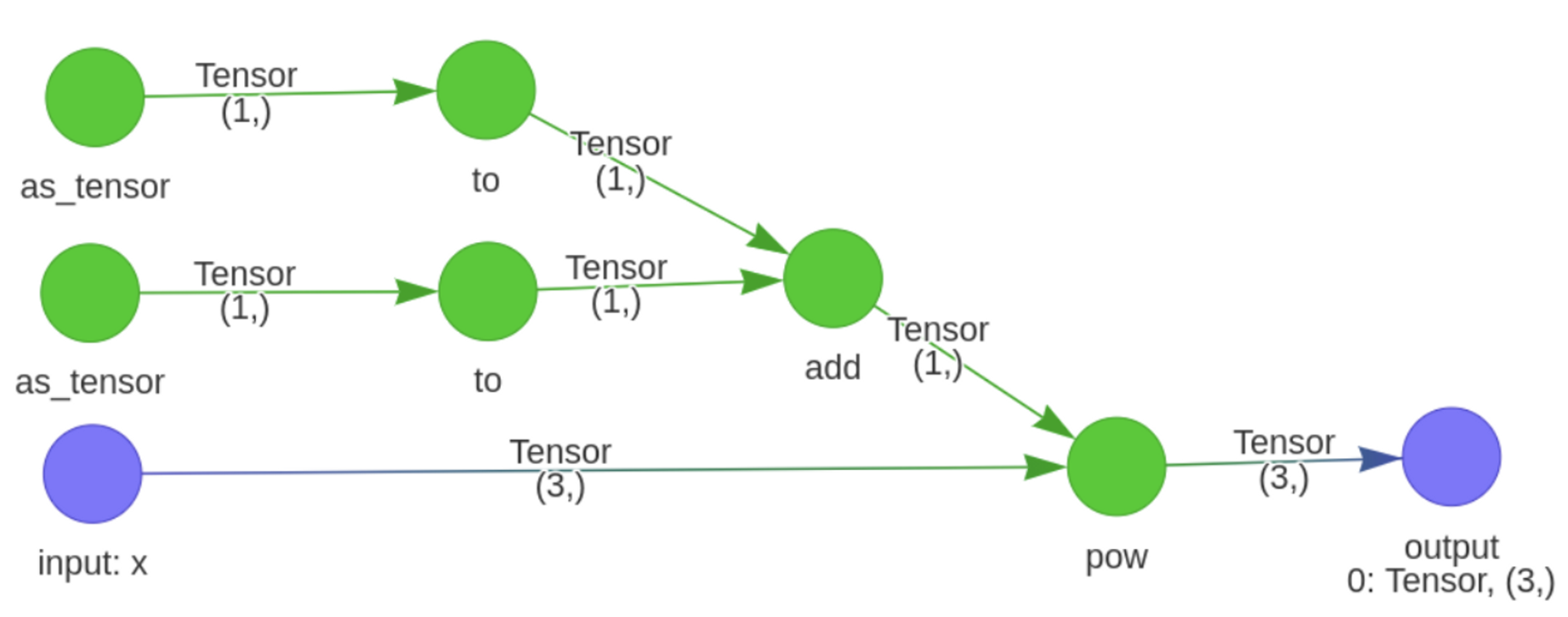
When calling ivy.trace_graph(), the array_caching argument is set to True by
default, which returns the following graph.

This shows that by caching the constant operation in the graph, a simpler graph can be
obtained. However, if desired, this argument can be set to False, which results in the
graph below. This ultimately results in a trade-off between time and memory, as
cached results need to be stored in memory but if they are not cached these operations
need to be performed.
Generators#
By using the include_generators argument, you can choose whether generator functions
are included as nodes or “baked” into the graph.
import ivy
ivy.set_backend("torch")
def fn(x):
a = torch.randint(0, 100, size=[1])
z = x ** a
return z + torch.rand([1])
comp_func = ivy.trace_graph(fn, include_generators=True, args=(x,))
Returns:
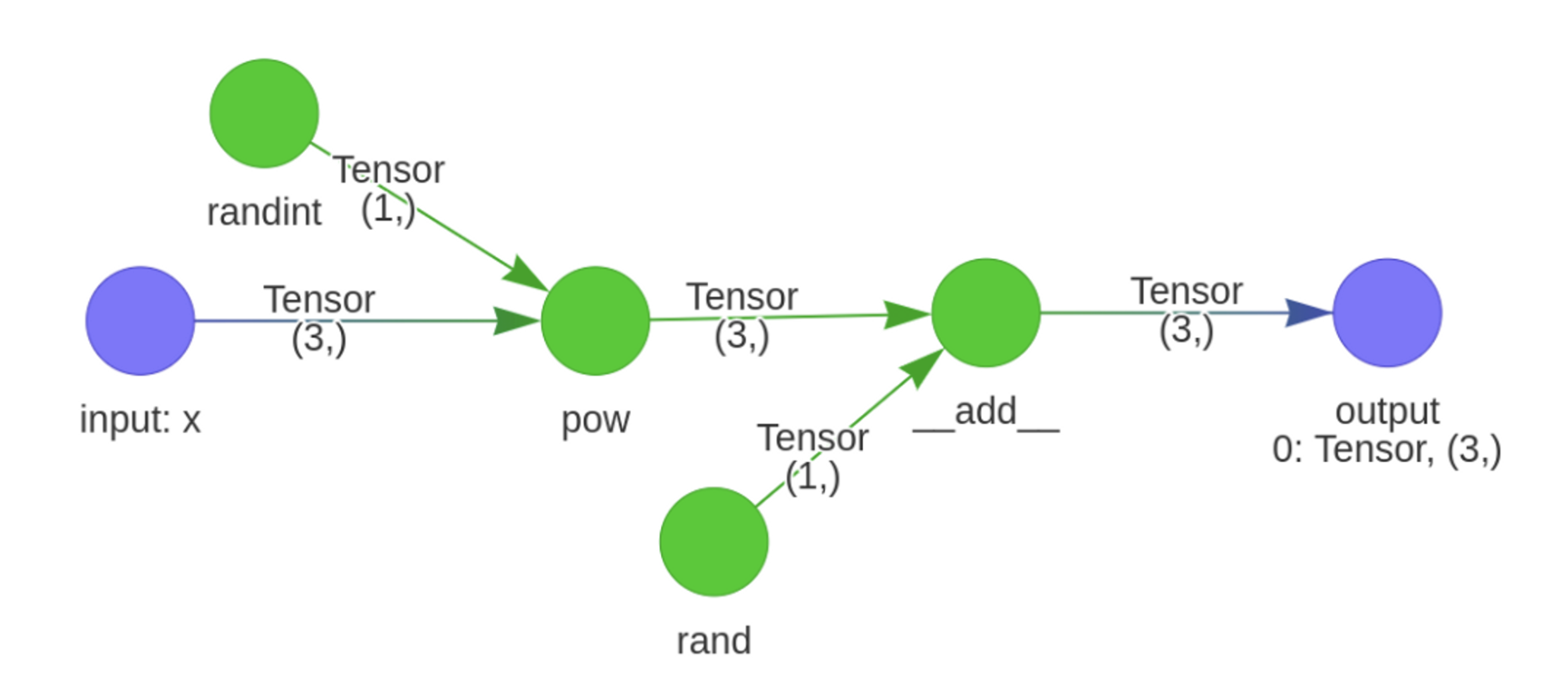
And instead,
import ivy
ivy.set_backend("torch")
def fn(x):
a = torch.randint(0, 100, size=[1])
z = x * a
return z + torch.rand([1])
comp_func = ivy.trace_graph(fn, include_generators=False, args=(x,))
Returns:

Stateful#
Finally, you can also track __setattr__ and __getattr__ methods of
arbitrary classes using the stateful parameters.
import ivy
ivy.set_backend("torch")
def fn(cont, x):
cont.new_attribute = x
return x + 1
x = torch.tensor([0])
cont = ivy.Container(x=x)
args = (cont.cont_deep_copy(), x)
comp_func = ivy.trace_graph(fn, arg_stateful_idxs=[[0]], args=args)
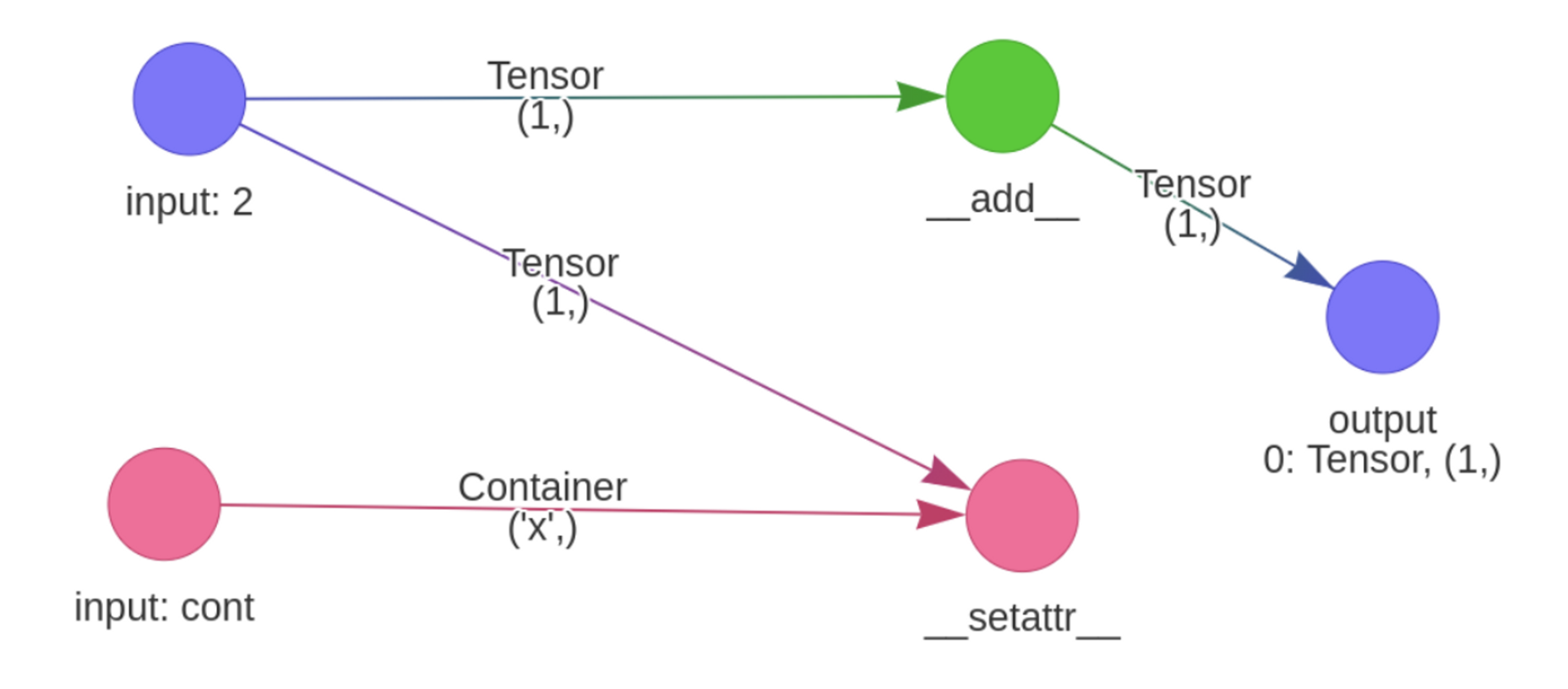
Examples#
Below, we trace a ResNet50 model from Hugging Face and use it to classify the breed of a cat.
import ivy
from transformers import AutoImageProcessor, ResNetForImageClassification
from datasets import load_dataset
# Set backend to torch
ivy.set_backend("torch")
# Download the input image
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
# Setting the model
image_processor = AutoImageProcessor.from_pretrained("microsoft/resnet-50")
model = ResNetForImageClassification.from_pretrained("microsoft/resnet-50")
# Preprocessing the input image
inputs = image_processor(image, return_tensors="pt")
Normally, we would then feed these inputs to the model itself without compiling it
# Normal flow using pytorch
with torch.no_grad():
logits = model(**inputs).logits
With ivy, you can trace your model to a computation graph for increased performance.
# Compiling the model
traced_graph = ivy.trace_graph(model, args=(**inputs,))
# Using the traced function
logits = traced_graph(**inputs).logits
Time for the final output of our computation graph.
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])