Ivy as a Transpiler#
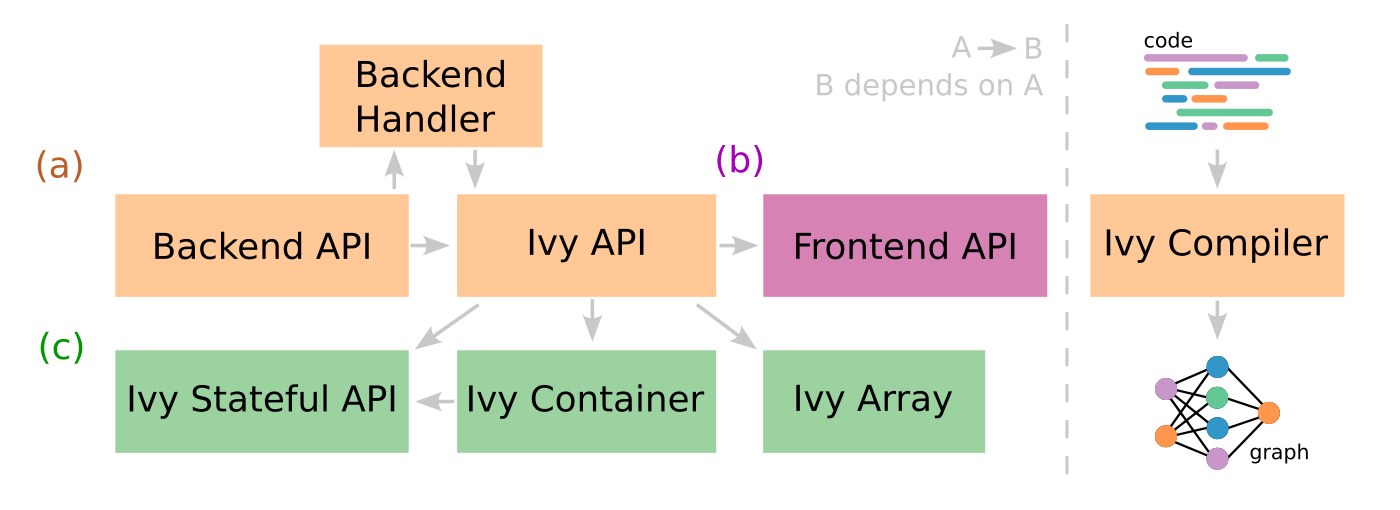
On the Building Blocks page, we explored the role of the Backend functional APIs, the Ivy functional API, the Backend handler, and the Tracer. These parts are labelled (a) in the image below.
Here, we explain the role of the backend-specific frontends in Ivy, and how these enable automatic code conversions between different ML frameworks. This part is labelled as (b) in the image below.
The code conversion tools described on this page are works in progress, as indicated by the construction signs 🚧. This is in keeping with the rest of the documentation.
Frontend Functional APIs 🚧#
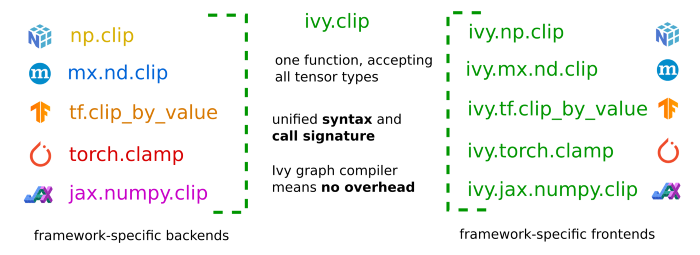
While the backend API, Ivy API, and backend handler enable all Ivy code to be framework-agnostic, they do not, for example, enable PyTorch code to be framework agnostic. But with frontend APIs, we can also achieve this!
Let’s take a look at how the implementation of clip method would seem like in the frontends:
# ivy/functional/frontends/jax/lax/functions.py
def clamp(x_min,x, x_max):
return ivy.clip(x, x_min, x_max)
# ivy/functional/frontends/numpy/general.py
def clip(x, x_min, x_max):
return ivy.clip(x, x_min, x_max)
# ivy/functional/frontends/tensorflow/general.py
def clip_by_value(x, x_min, x_max):
return ivy.clip(x, x_min, x_max)
# ivy/functional/frontends/torch/general.py
def clamp(x, x_min, x_max):
return ivy.clip(x, x_min, x_max)
combined, we have the following situation:
Importantly, we can select the backend and frontend independently from one another. For example, this means we can select a JAX backend, but also select the PyTorch frontend and write Ivy code which fully adheres to the PyTorch functional API. In the reverse direction: we can take pre-written pure PyTorch code, replace each PyTorch function with the equivalent function using Ivy’s PyTorch frontend, and then run this PyTorch code using JAX:
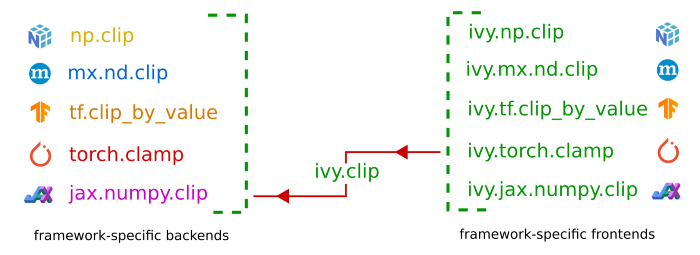
For this example it’s very simple, the differences are only syntactic, but the above process works for any function. If there are semantic differences then these will be captured (a) in the wrapped frontend code which expresses the frontend method as a composition of Ivy functions, and (b) in the wrapped backend code which expressed the Ivy functions as compositions of backend methods.
Let’s take a more complex example and convert the PyTorch method torch.nn.functional.one_hot() into NumPy code.
The frontend is implemented by wrapping a single Ivy method ivy.one_hot() as follows:
# ivy/functional/frontends/torch/nn/sparse_functions.py
def one_hot(tensor, num_classes=-1):
return ivy.one_hot(tensor, num_classes)
Let’s look at the NumPy backend code for this Ivy method:
# ivy/functional/backends/numpy/general.py
def one_hot(
indices: np.ndarray, depth: int, *, device: str, out: Optional[np.ndarray] = None
) -> np.ndarray:
res = np.eye(depth)[np.array(indices).reshape(-1)]
return res.reshape(list(indices.shape) + [depth])
By chaining these methods together, we can now call torch.nn.functional.one_hot() using NumPy:
import ivy
import ivy.frontends.torch as torch
ivy.set_backend('numpy')
x = np.array([0., 1., 2.])
ret = torch.nn.functional.one_hot(x, 3)
Let’s take one more example and convert TensorFlow method tf.cumprod() into PyTorch code.
This time, the frontend is implemented by wrapping two Ivy methods ivy.cumprod(), and ivy.flip() as follows:
# ivy/functional/frontends/tensorflow/math.py
def cumprod(x, axis=0, exclusive=False, reverse=False, name=None):
ret = ivy.cumprod(x, axis, exclusive)
if reverse:
return ivy.flip(ret, axis)
return ret
Let’s look at the PyTorch backend code for both of these Ivy methods:
# ivy/functional/backends/torch/general.py
def cumprod(
x: torch.Tensor,
axis: int = 0,
exclusive: bool = False,
*,
out: Optional[torch.Tensor] = None,
) -> torch.Tensor:
if exclusive:
x = torch.transpose(x, axis, -1)
x = torch.cat((torch.ones_like(x[..., -1:]), x[..., :-1]), -1, out=out)
res = torch.cumprod(x, -1, out=out)
return torch.transpose(res, axis, -1)
return torch.cumprod(x, axis, out=out)
# ivy/functional/backends/torch/manipulation.py
def flip(
x: torch.Tensor,
axis: Optional[Union[int, Sequence[int]]] = None,
*,
out: Optional[torch.Tensor] = None,
) -> torch.Tensor:
num_dims: int = len(x.shape)
if not num_dims:
return x
if axis is None:
new_axis: List[int] = list(range(num_dims))
else:
new_axis: List[int] = axis
if isinstance(new_axis, int):
new_axis = [new_axis]
else:
new_axis = new_axis
new_axis = [item + num_dims if item < 0 else item for item in new_axis]
ret = torch.flip(x, new_axis)
return ret
Again, by chaining these methods together, we can now call tf.math.cumprod() using PyTorch:
import ivy
import ivy.frontends.tensorflow as tf
ivy.set_backend('torch')
x = torch.tensor([[0., 1., 2.]])
ret = tf.math.cumprod(x, -1)
Role of the Tracer 🚧#
The very simple example above worked well, but what about even more complex PyTorch code involving Modules, Optimizers, and other higher level objects? This is where the tracer plays a vital role. The tracer can convert any code into its constituent functions at the functional API level for any ML framework.
For example, let’s take the following PyTorch code and run it using JAX:
import torch
class Network(torch.nn.Module):
def __init__(self):
super().__init__()
self._linear = torch.nn.Linear(3, 3)
def forward(self, x):
return self._linear(x)
x = torch.tensor([1., 2., 3.])
net = Network()
net(x)
We cannot simply import ivy.frontends.torch in place of import torch as we did in the previous examples.
This is because the Ivy frontend only supports the functional API for each framework, whereas the code above makes use of higher level classes through the use of the torch.nn namespace.
In general, the way we convert code is by first decomposing the code into its constituent functions in the core API using Ivy’s tracer, and then we convert this executable graph into the new framework. For the example above, this would look like:
import jax
import ivy
jax_graph = ivy.trace_graph(net, x).to_backend('jax')
x = jax.numpy.array([1., 2., 3.])
jax_graph(x)
However, when calling ivy.trace() the graph only connects the inputs to the outputs.
Any other tensors or variables which are not listed in the inputs are treated as constants in the graph.
In this case, this means the learnable weights in the Module will be treated as constants.
This works fine if we only care about running inference on our graph post-training, but this won’t enable training of the Module in JAX.
Converting Network Models 🚧#
In order to convert a model from PyTorch to JAX, we first must convert the torch.nn.Module instance to an ivy.Module instance using the method ivy.to_ivy_module() like so:
net = ivy.to_ivy_module(net)
In its current form, the ivy.Module instance thinly wraps the PyTorch model into the ivy.Module interface, whilst preserving the pure PyTorch backend.
We can trace a graph of this network using Ivy’s tracer like so:
net = net.trace_graph()
In this case, the learnable weights are treated as inputs to the graph rather than constants.
Now, with a traced graph under the hood of our model, we can call to_backend() directly on the ivy.Module instance to convert it to any backend of our choosing, like so:
net = net.to_backend('jax')
The network can now be trained using Ivy’s optimizer classes with a JAX backend like so:
optimizer = ivy.Adam(1e-4)
x_in = ivy.array([1., 2., 3.])
target = ivy.array([0.])
def loss_fn(v):
out = model(x_in, v=v)
return ivy.reduce_mean((out - target)**2)
for step in range(100):
loss, grads = ivy.execute_with_gradients(loss_fn, model.v)
model.v = optimizer.step(model.v, grads)
To convert this ivy.Module instance to a haiku.Module instance, we can call to_haiku_module() like so:
net = net.to_haiku_module()
If we want to remove Ivy from the pipeline entirely, we can then train the model in Haiku like so:
import haiku as hk
import jax.numpy as jnp
x_in = jnp.array([1., 2., 3.])
target = jnp.array([0.])
def loss_fn():
out = net(x_in)
return jnp.mean((out - target)**2)
loss_fn_t = hk.transform(loss_fn)
loss_fn_t = hk.without_apply_rng(loss_fn_t)
rng = jax.random.PRNGKey(42)
params = loss_fn_t.init(rng)
def update_rule(param, update):
return param - 0.01 * update
for i in range(100):
grads = jax.grad(loss_fn_t.apply)(params)
params = jax.tree_multimap(update_rule, params, grads)
Other JAX-specific network libraries such as Flax, Trax, and Objax are also supported.
Overall, we have taken a torch.nn.Module instance, which can be trained using PyTorch’s optimizer classes, and converted this to a haiku.Module instance which can be trained using Haiku’s optimizer classes.
The same is true for any combination of frameworks, and for any network architecture, regardless of its complexity!
Round Up
Hopefully, this has explained how, with the addition of backend-specific frontends, Ivy will be able to easily convert code between different ML frameworks 🙂 works in progress, as indicated by the construction signs 🚧. This is in keeping with the rest of the documentation.
Please reach out on discord if you have any questions!