Continuous Integration#
We follow the practice of Continuous Integration (CI), in order to regularly build and test code at Ivy. This makes sure that:
Developers get feedback on their code soon, and Errors in the Code are detected quickly. ✅
The developer can easily debug the code when finding the source of an error, and rollback changes in case of Issues. 🔍
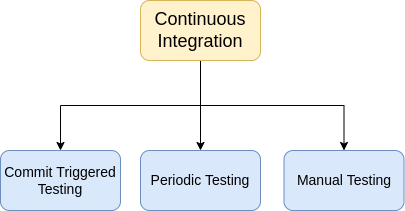
In order to incorporate Continuous Integration in the Ivy Repository, we follow a three-fold technique, which involves:
Commit Triggered Testing
Periodic Testing
Manual Testing
We use GitHub Actions in order to implement and automate the process of testing. GitHub Actions allow implementing custom workflows that can build the code in the repository and run the tests. All the workflows used by Ivy are defined in the .github/workflows directory.
Commit (Push/PR) Triggered Testing#
A small subset of the following tests are triggered in case of a Commit (Push/PR) made to the Ivy Repository:
Ivy Tests
Array API Tests
Ivy Tests#
A test is defined as the triplet of (submodule, function, backend). We follow the following notation to identify each test:
submodule::function,backend
For example, ivy_tests/test_ivy/test_frontends/test_torch/test_tensor.py::test_torch_instance_arctan_,numpy
The Number of such Ivy tests running on the Repository (without taking any Framework/Python Versioning into account) is 12500 (as of writing this documentation), and we are adding tests daily. Therefore, triggering all the tests on each commit is neither desirable (as it will consume a huge lot of Compute Resources, as well as take a large amount of time to run) nor feasible (as Each Job in Github Actions has a time Limit of 360 Minutes, and a Memory Limit as well).
Further, When we consider versioning, for a single Python version, and ~40 frontend and backend versions, the tests would shoot up to 40 * 40 * 12500 = 20,000,000, and we obviously don’t have resources as well as time to run those many tests on each commit.
Thus, We need to prune the tests that run on each push to the Github Repository. The ideal situation, here, is to trigger only the tests that are impacted by the changes made in a push. The tests that are not impacted by the changes made in a push, are wasteful to trigger, as their results don’t change (keeping the same Hypothesis Configuration). For example, Consider the commit
The commit changes the _reduce_loss function and the binary_cross_entropy functions in the ivy/functional/ivy/losses.py file. The only tests that must be triggered (for all 5 backends) are:
ivy_tests/test_ivy/test_functional/test_nn/test_losses.py::test_binary_cross_entropy_with_logits
ivy_tests/test_ivy/test_functional/test_nn/test_losses.py::test_cross_entropy
ivy_tests/test_ivy/test_functional/test_nn/test_losses.py::test_binary_cross_entropy
ivy_tests/test_ivy/test_functional/test_nn/test_losses.py::test_sparse_cross_entropy
ivy_tests/test_ivy/test_frontends/test_torch/test_loss_functions.py::test_torch_binary_cross_entropy
ivy_tests/test_ivy/test_frontends/test_torch/test_loss_functions.py::test_torch_cross_entropy
Ivy’s Functional API functions binary_cross_entropy_with_logits, test_cross_entropy, test_binary_cross_entropy, test_sparse_cross_entropy, are precisely the ones impacted by the changes in the commit, and since the torch Frontend Functions torch_binary_cross_entropy, and torch_cross_entropy are wrapping these, the corresponding frontend tests are also impacted. No other Frontend function calls these underneath and hence should not be triggered.
How do we (or at least try to) achieve this?
Implementation#
A Top-Down View#
In order to implement this, we use the magic of Test Coverage! Test Coverage refers to finding statements (lines) in your code that are executed (or could have been executed), on running a particular test.
We use the Python Coverage Package (https://coverage.readthedocs.io/en/7.0.0/) for determining the Test Coverage of our tests.
The way it works is by running a particular pytest, and then logging each line (of our code) that was executed (or could have been executed) by the test.
Computing Test Coverage for all Ivy tests, allows us to find, for each line of code, which tests affect the same. We create a Dictionary (Mapping) to store this information as follows (The actual Mapping we prepare is a bit different from this design, but we will follow this for now due to Pedagogical Purposes):
The dictionary thus stores a list for each file \(f_1 … f_m\). The list is a sequence encapsulating the lines of the file. Each index of the list contains a set of tests, which are mapped to the corresponding line in the file.
Given this Mapping for a commit, We can just follow the below procedure:
Find the files which are changed in the commit, and check for lines that are added/deleted/updated in the file.
Determine the Tests that impact the lines, and trigger just those tests, and no others.
But, there’s a fundamental issue here, Computing the Mapping requires determining the coverage for all tests, which involves running all the tests. Doesn’t this sound cyclical? After all, We are doing all this to avoid running all the tests.
Now assume that we had some way to update the Mapping for a commit from the previous Mapping without having to run all the tests. Then, Given the Mapping for a single commit, we could follow this to determine and run the relevant tests for each commit as follows:
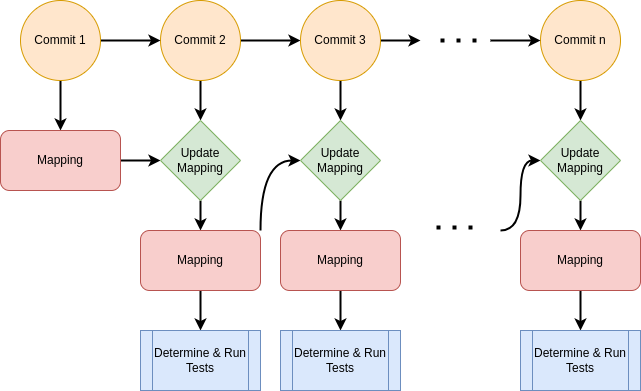
This is exactly what we do in order to implement Intelligent Testing. The “Update Mapping” Logic works as follows for each changed file:
For each deleted line, we remove the corresponding entry from the list corresponding to the file in the Mapping.
tests_file = tests[file_name]
for line in sorted(deleted, reverse=True):
if line < len(tests_file):
del tests_file[line]
For each line added, we compute the tests as an intersection of the set of tests on the line above and below the line.
for line in added:
top = -1
bottom = -1
if 0 <= line - 1 < len(tests_file):
top = tests_file[line - 1]
if 0 <= line + 1 < len(tests_file):
bottom = tests_file[line + 1]
tests_line = set()
if top != -1 and bottom != -1:
tests_line = top.intersection(bottom)
elif top != -1:
tests_line = top
elif bottom != -1:
tests_line = bottom
tests_file.insert(line, tests_line)
tests[file_name] = tests_file
Finally, For newly added tests, we compute the coverage of the new tests (limited to 10 per commit), and update the Mapping correspondingly.
Once the Mapping has been updated, the “Determine & Run Tests” Logic works as follows:
For each deleted line, we collect the tests corresponding to the line as:
for line in deleted:
tests_to_run = determine_tests_line(tests_file, line, tests_to_run)
For each line updated, we collect the tests corresponding to the line as:
for line in updated:
tests_to_run = determine_tests_line(tests_file, line, tests_to_run)
For each line added, we collect the tests corresponding to the line as:
for line in added:
tests_to_run = determine_tests_line(tests_file, line, tests_to_run)
Further, All the new tests added in a commit are collected (up to a max limit of 10, any more tests added are taken up in subsequent commits).
Finally, All the collected tests are triggered by the scripts/run_tests/run_tests.py script, and the corresponding entry in the MongoDB Database is updated with the Test Result (Details on this in the Dashboard Section below).
Storing (and retrieving) the Mapping#
As we see in the overview section, we compute a mapping of lines to tests, for each commit to the Ivy Repository. This mapping has to be stored somewhere, in order to be used by a future commit to determine the corresponding mapping (and therefore, trigger the required tests). Therefore, we need a mechanism to store and retrieve the Mapping. We use the unifyai/Mapping GitHub Repository for this purpose. We use a GitHub Repository for the following reasons:
Unlike Specialized Databases (like Google Cloud), we need not store any specialized secrets to access the Database (separately for reading and writing), and no separate API Keys are required for updating the DB, saving us from exposing our secret key Files (from GitHub Actions). In fact, We just except for a single SSH Deploy Key (secrets.SSH_DEPLOY_KEY) required for pushing the DB.
The Repository is a Public Repository, and thus can be read by anyone, while the push can be restricted. This makes it helpful to expose the Mapping to run tests on the PRs, while allowing only the Push Commits to update the Mapping.
We don’t need to make any specialized API Calls to Read/Write/Update the Mapping (Cloning and Pushing to the Repo suffices).
Finally, It saves us from a Massive Race Condition Issue (which we highlight below).
A GitHub Repository is not the best DB, obviously, with its own set of constraints (ex. 100 MB Space Limit), but works well enough for our requirements.
Cloning and Pushing to the Repository#
For Push triggered testing (intelligent-tests.yml Workflow), we use the SSH Cloning Method in order to felicitate the clone and push commands to the Repository, as follows:
source ./ivy/scripts/shell/clone_mapping.sh master
Determine and Run Tests, and Update the Mapping ...
git add .
git commit -m "Update Mapping"
git push origin master
The clone_mapping file works as follows: It creates a Directory called .ssh in the HOME folder of the VM hosted by GitHub, and copies the Deploy Key into the deploy_key file within the folder. Further, it adds github.com to the list of SSH Known Hosts. Now, that the SSH key of the Runner has permissions to push and clone the Mapping repository, it simply calls the git clone command. It does so with fetch depth set to 1, in order to just clone the latest commit, and no other.
USER_EMAIL="ivy.branch@lets-unify.ai"
USER_NAME="ivy-branch"
TARGET_BRANCH=$1
GITHUB_SERVER="github.com"
mkdir --parents "$HOME/.ssh"
DEPLOY_KEY_FILE="$HOME/.ssh/deploy_key"
echo "${SSH_DEPLOY_KEY}" > "$DEPLOY_KEY_FILE"
chmod 600 "$DEPLOY_KEY_FILE"
SSH_KNOWN_HOSTS_FILE="$HOME/.ssh/known_hosts"
ssh-keyscan -H "$GITHUB_SERVER" > "$SSH_KNOWN_HOSTS_FILE"
export GIT_SSH_COMMAND="ssh -i "$DEPLOY_KEY_FILE" -o UserKnownHostsFile=$SSH_KNOWN_HOSTS_FILE"
# Setup git
git config --global user.email "$USER_EMAIL"
git config --global user.name "$USER_NAME"
git clone --single-branch --depth 1 --branch "$TARGET_BRANCH" git@github.com:unifyai/Mapping.git
In the case of, Pull Requests, we do not have access to SSH_DEPLOY_KEY secret (and we don’t even want to give PRs that access), and thus we don’t use the SSH Clone Methodology and instead use the HTTP Clone Method, as follows:
git clone -b master1 https://github.com/unifyai/Mapping.git --depth 1
Determine and Run the Tests ...
PRs should not update the Mapping on the Repository, and thus no Push is required in case of PRs.
Implementational Nitty Gritties#
Storage Space (unifyai/Mapping)#
The GitHub Repository allows only storing 100 MB of files per commit. The current design of the mapping takes a huge space as test names are long strings and are stored repeatedly for each line that is impacted by the tests. In order to reduce the space requirement for storing the Mapping, we restructure the Mapping as follows:
We include the index_mapping and the test_mapping fields, which map indices to tests and tests to indices, respectively. This allows us to just store the test index for each line in the Mapping, reducing the storage requirement significantly.
Determine Test Coverage Workflow#
Since each of our Update Mapping routine is not precisely correct, the Mapping would keep aggregating incorrections as commits keep coming to the GitHub Repository. In order to prevent this snowball effect from running completely irrelevant tests on each commit, we need to recalibrate the Mapping periodically. This is done by the Determine Test Coverage Workflow (implemented in det-test-coverage.yml).
name: determine-test-coverage
on:
workflow_dispatch:
schedule:
- cron: "30 20 * * 6"
Notice that the workflow triggers every Saturday Night at 8.30 PM (Fun Fact: It’s just my gut feeling that there are relatively lesser commits on the Repository on a Saturday Night, and we get access to the Resources quickly, LoL!).
The workflow runs all the Ivy tests, determines their coverage, computes the Mapping, and pushes it to the unifyai/Mapping Repository.
Multiple Runners#
The Determine Test Coverage workflow takes about ~60 hours to complete if run with a single runner. The GitHub Action rules don’t allow running a single Job for more than 6 hours. Further, Determining the Coverage
Therefore, we need to split the Workflow based on the Tests (into 32 runners). Each runner caters to its own subset of tests, and is responsible for determining the coverage for only those tests, and creates the Mapping based on these tests.
Therefore, we have 32 branches (master1, master2, …, master32), on the unifyai/Mapping Repository, and also 32 runners on the intelligent-tests and intelligent-tests-pr Workflows.
Everything sounds good, but Can you think of a potential Race Condition here?
Race Condition#
The Synchronized Object here is the unifyai/Mapping Repository, and is accessed through push (Write) and pull (Read) to the Repository. The Determine Test Coverage Workflow and the Intelligent Tests Workflow can run concurrently, while both of them write to the Mapping Repository. Consider the following Case for Runner 2:
The Determine Test Coverage workflow has been running, and is about to complete for Runner 2. Meanwhile, a commit made on the master triggers the intelligent-tests workflow.
The runner 2 in the intelligent-tests workflow, pulls the Mapping from the master2 branch of the unifyai/Mapping repository, and starts running the determined tests (based on changes made in the commit).
The det-test-coverage workflow completes for runner2, which makes a push to the corresponding branch in the unifyai/Mapping Repository.
The runner 2 in the intelligent-tests workflow also completes, and pushes the updated repository
Thus, in the end, the push from the det-test-coverage would be completely ignored, and the system would not be recalibrated. Further, For some other Runner(s), the final push may be done by the Determine Test Coverage Workflow, and thus, the test distribution in itself might be corrupted (Overlapping Tests and Missing Tests).
We handle the Race Condition as follows:
The Intelligent Tests workflow is allowed to push to the repository only when there is no merge conflict, while the Determine Test Coverage Workflow makes a force push (-f) push.
Therefore, when the above situation occurs, the Push from Intelligent Tests workflow is discarded, while the recalibration push stays in place, and leads to consistency among runners, as well as, corrects the Coverage.
Array API Tests#
The array-api-intelligent-tests.yml (Push) and the array-api-intelligent-tests-pr.yml (Pull Request) workflows run the Array API Tests. Similar to Ivy Tests, The Array API tests are also determined intelligently and only relevant tests are triggered on each commit.
More details about the Array API Tests are available here.
Periodic Testing#
In order to make sure that none of the Ivy Tests are left ignored for a long time, and to decouple the rate of testing to the rate of committing to the repository, we implement periodic testing on the Ivy Repository. The Test Ivy Cron Workflow is responsible for implementing this behavior by running Ivy tests every hour. In Each Run, It triggers 150 Ivy Tests, cycling through all of the tests. This number of 150 is chosen in order to make sure that the Action completes in 1 hour most of the time. The Test Results update the corresponding cell on the Dashboards.
Manually Dispatched Workflows#
In order to trigger any particular test for any reason (maybe Intelligent Testing missed the Test), you can follow the following steps:
Visit GitHub Actions
Click on Run Workflow
Add the Name of the test as:
ivy_tests/test_ivy/test_frontends/test_torch/test_tensor.py::test_torch_instance_arctan_If you want the test to be triggered for a particular Backend, append it with a “,” as:
ivy_tests/test_ivy/test_frontends/test_torch/test_tensor.py::test_torch_instance_arctan_,tensorflowLeave the Version Based Testing and GPU Testing Options as false.
Check the result there and then itself, or wait for the dashboard to update.
Manual Tests are also available for PRs. You can also run the Manual Tests Workflow on a Fork Repository (while reviewing PRs), as follows:
Visit the “Actions” Tab on the Fork, and selecting the manual-tests-pr workflow from the left pane.
Trigger the Workflow by following Steps 2-4 described above.
This might take some time to run as the Fork may have limited runners.
CI Pipeline ➡️#
The below subsections provide the roadmap for running workflows and interpreting results in case a push or a pull request is made to the repository.
Push#
Whenever a push is made to the repository, a variety of workflows are triggered automatically (as described above). This can be seen on the GitHub Repository Page, with the commit message followed by a yellow dot, indicating that some workflows have been queued to run following this commit, as shown below:

Clicking on the yellow dot (🟡) (which changes to a tick (✔) or cross (❌), when the tests have been completed) yields a view of the test-suite results as shown below:

Click on the “Details” link corresponding to the failing tests, in order to identify the cause of the failure. It redirects to the Actions Tab, showing details of the failure, as shown below:
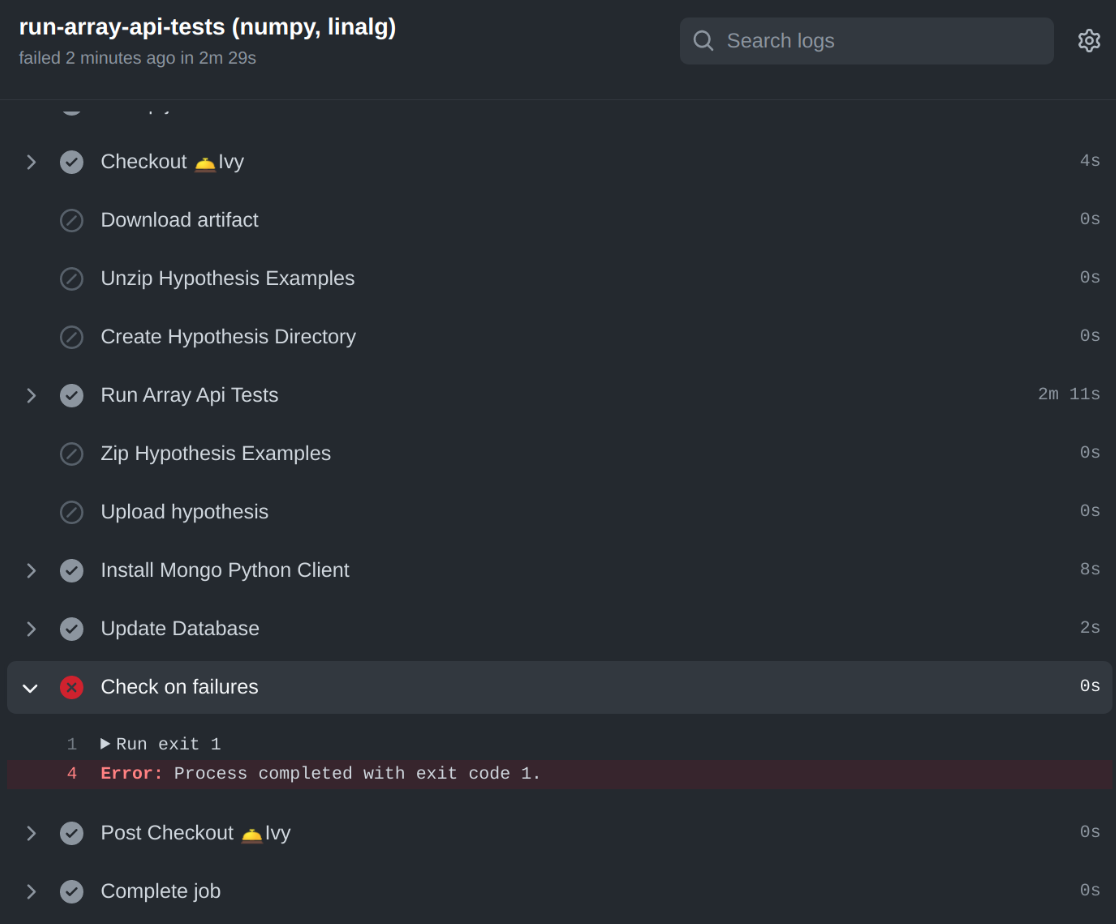
Click on the “Run Tests” section in order to see the logs of the failing tests for Array API Tests. For Ivy Tests, head to the “Combined Test Results” Section of the display-test-results Job, which shows the Test Logs for each of the tests in the following format:
***************************************************
Test 1
***************************************************
Hypothesis Logs for Test 1 (Indicates Failure/Success)
***************************************************
Test 2
***************************************************
Hypothesis Logs for Test 2 (Indicates Failure/Success)
…
***************************************************
Test n
***************************************************
Hypothesis Logs for Test n (Indicates Failure/Success)
You can ignore the other sections of the Workflow, as they are for book-keeping and implementation purposes. You can also directly refer to the Dashboard (available at https://ivy-dynamical-dashboards.onrender.com), to check the result of your test.
Pull Request#
In case of a pull request, the test suite is available on the Pull Request Page on Github, as shown below:
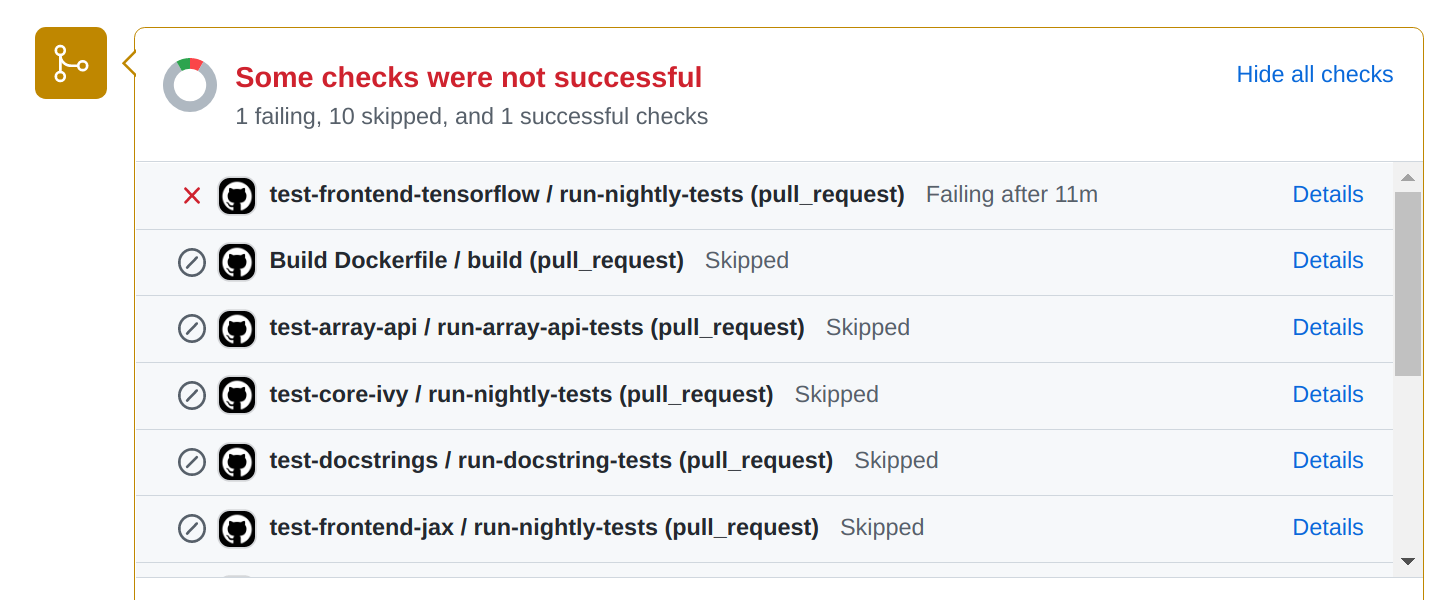
Clicking on the “Details” link redirects to the Action Log. The rest of the procedure remains the same as given in the Push section above.
As an added feature, the Intelligent Tests for PR Workflow has a section on “New Failures Introduced” in the display-test-results jos, which lists the details of tests that are failing on the PR Fork/Branch but not on the master branch. When creating a PR, make sure that your PR does not introduce any new failures.
Dashboard#
In order to view the status of the tests, at any point in time, we have implemented a dashboard application that shows the results of the latest Workflow that ran each test. The Dashboards are available at the link: https://ivy-dynamical-dashboards.onrender.com You can filter tests by selecting choices from the various dropdowns. The link can also be saved for redirecting straight to the filtered tests in the future. The status badges are clickable, and will take you directly to the Action log of the latest workflow that ran the corresponding test.
Round Up
This should have hopefully given you a good feel for how Continuous Integration works in Ivy.
If you have any questions, please feel free to reach out on discord in the `continuous integration thread`_!
Video