![]()
How To Convert Models from PyTorch to PaddlePaddle#
Whenever a new SOTA model comes onto the scene, this is almost always followed with a HuggingFace implementation, and almost always in PyTorch. While this is generally a great thing, it’s not so convenient for non-PyTorch users, who must manually reimplement the model into their frameworks of choice! 😮💨
PaddlePaddle is a very popular, open source, machine learning framework used by thousands of practitioners, especially in China. However, PaddlePaddle suffers from the problem described above.
This demo shows how you can convert a PyTorch model from HuggingFace to PaddlePaddle! Specifically, we’ll be transpiling dinov2 🦖
About the Model#
DINOv2 is the second iteration of the DINO model, developed by Meta. It is a self-supervised Vision Transformer (ViT) that produces general-purpose visual features from images. Given the abundant literature on the model, we’ll be mainly focusing on being able to transpile this model rather than the granular details of the model itself. Interested readers might want to go through this blog.
Transpiling the Model#
Let’s get started! We first need to import necessary libraries:
[1]:
!pip install -q ivy
!pip install -q paddlepaddle-gpu
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 16.4/16.4 MB 13.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 44.6/44.6 kB 6.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 45.5/45.5 kB 7.1 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 143.8/143.8 kB 15.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 756.0/756.0 kB 65.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 116.3/116.3 kB 15.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 59.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 749.8/749.8 MB 1.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 75.6/75.6 kB 11.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.8/77.8 kB 11.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.3/58.3 kB 9.4 MB/s eta 0:00:00
[2]:
%env FLAGS_fraction_of_gpu_memory_to_use=auto_growth
import requests
from tqdm import tqdm
from PIL import Image
import torch
import paddle
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
import ivy
device = "gpu" if paddle.device.cuda.device_count() else "cpu"
torch.manual_seed(0)
paddle.seed(0)
env: FLAGS_fraction_of_gpu_memory_to_use=auto_growth
[2]:
<paddle.base.libpaddle.Generator at 0x7c8738e15470>
Next, we load an image to be passed as the input for transpilation:
[3]:
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
[4]:
image
[4]:

Let’s create the model:
[5]:
processor = AutoImageProcessor.from_pretrained("facebook/dinov2-base-imagenet1k-1-layer")
model = AutoModelForImageClassification.from_pretrained("facebook/dinov2-base-imagenet1k-1-layer")
id2label = model.config.id2label
We pass in the inputs to the original model, the model classifies the input to “tabby, tabby cat”:
[6]:
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
logits_np = logits.detach().cpu().numpy()
predicted_class_idx = logits.argmax(-1).item()
print(f"Predicted class : {id2label[predicted_class_idx]}")
Predicted class : tabby, tabby cat
Now, we will transpile the model to PaddlePaddle using ivy.transpile, here’s a simple example explaining the usage.
[7]:
transpiled_model = ivy.transpile(model, kwargs=inputs, source="torch", to="paddle")
/usr/local/lib/python3.10/dist-packages/ivy/utils/exceptions.py:383: UserWarning: The current backend: 'paddle' does not support inplace updates natively. Ivy would quietly create new arrays when using inplace updates with this backend, leading to memory overhead (same applies for views). If you want to control your memory management, consider doing ivy.set_inplace_mode('strict') which should raise an error whenever an inplace update is attempted with this backend.
warnings.warn(
Comparing the results#
Let’s now try predicting the class of the same input with the transpiled model:
[8]:
paddle_inputs = {"pixel_values": paddle.to_tensor(inputs["pixel_values"].cpu().numpy(), stop_gradient=False, place="cpu")}
outputs = transpiled_model(**paddle_inputs)
logits = outputs.logits
logits_np_transpiled = logits.numpy()
predicted_class_idx = paddle.argmax(logits, -1)
print("Predicted class transpiled:", id2label[int(predicted_class_idx[0])])
Predicted class transpiled: tabby, tabby cat
As you can see, the transpiled model predicted the same class as the input. But to compare the logits produced by the original and transpiled models at a more granular level, let’s try an allclose:
[9]:
print(f"All Close : {np.allclose(logits_np, logits_np_transpiled, rtol=1e-4, atol=1e-4)}")
All Close : True
The logits produced by the transpiled model at inference time are within the 4th decimal compared to the original model, the logits are indeed consistent!
Fine-tuning the transpiled model#
One of the key benefits of using ivy’s transpiler is that the transpiled model is also trainable. As a result, we can also further train the transpiled model if required. Here’s an example of fine-tuning the transpiled model with a few images sampled from CIFAR-10 using PaddlePaddle.
We start by importing the necessary paddle libraries:
[10]:
from paddle.vision.datasets import Cifar10
from paddle.io import DataLoader
from paddle.optimizer import SGD
import paddle.vision.transforms as T
import paddle.nn.functional as F
We create the dataset, dataloader and optimizer:
[11]:
transform = T.Compose(
[
T.Resize(224),
T.ToTensor(),
T.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5],
to_rgb=True,
),
]
)
cifar10 = Cifar10(mode="test", transform=transform, backend="cv2")
cifar10.data = cifar10.data[:100]
dataloader = DataLoader(cifar10, batch_size=4, shuffle=True, drop_last=True, num_workers=2)
opt = SGD(learning_rate=1e-3, parameters=transpiled_model.parameters())
Cache file /root/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz
Begin to download
item 41626/41626 [============================>.] - ETA: 0s - 2ms/item
Download finished
We then set-up our training loop:
[12]:
transpiled_model = transpiled_model.to(device)
epochs = 5
loss_epoch_arr = []
for epoch in tqdm(range(epochs)):
loss_arr = []
for i, (image, label) in enumerate(dataloader()):
image.stop_gradient = False
logits = transpiled_model(pixel_values=image).logits
probs = F.softmax(logits, axis=-1)
loss = F.cross_entropy(probs, label)
loss.backward()
opt.step()
loss_arr.append(loss.item())
avg_loss = sum(loss_arr) / len(loss_arr)
loss_epoch_arr.append(avg_loss)
100%|██████████| 5/5 [01:21<00:00, 16.33s/it]
Here’s a graph of the average loss over the epochs we’ve trained the model:
[13]:
import matplotlib.pyplot as plt
plt.plot(loss_epoch_arr)
plt.show()
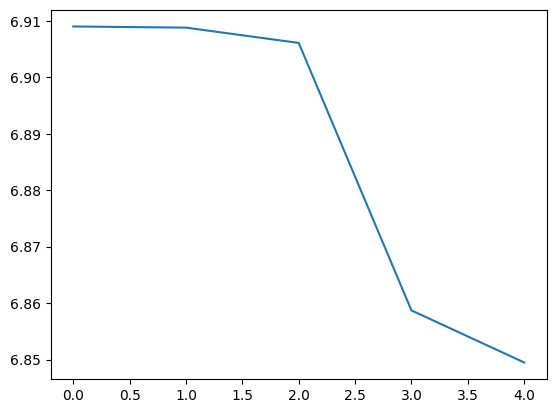
And that’s it, we’ve successfully been able to train the transpiled model!
Conclusion#
As promised, we’ve demonstrated how you can use ivy’s transpiler to bring a PyTorch model from HuggingFace into a PaddlePaddle pipeline. We hope you found this demo useful!
Head over to the tutorials section in our documentation if you’d like to explore other demos like this. You can also run demos locally on your own machine by signing up to get a transpiler API key for local development.
If you have any questions, feel free to ask on our Discord community server, we look forward to seeing you there!