Routing#
In this section, you will learn what LLM routing is and how it works.
What is routing?#
In the benchmarks section, we discussed how different models perform better at different tasks, and how appropriate performance benchmarks can help steer and inform model selection for a given use-case.
Given the diversity of prompts you can send to an LLM, it can quickly become tedious to manually swap between models for every single prompt, even when they pertain to the same broad category of tasks.
Motivated by this, LLM routing aims to make optimal model selection automatic. With a router, each prompt is assessed individually and sent to the best model, without having to tweak the LLM pipeline. With routing, you can focus on prompting and ensure that the best model is always on the receiving end!
Quality routing#
By routing to the best LLM on every prompt, the objective is to consistently achieve better outputs than using a single, all-purpose, powerful mode, at a fraction of the cost. The idea is that smaller models can be leveraged for some simpler tasks, only using larger models to handle complex queries.
Using several datasets to benchmark the router (star-shaped datapoints) reveals that it can perform better than individual endpoints on average, without compromising on other metrics like runtime performance for e.g, as illustrated below.

You may notice that there are more than one star-shaped datapoints on the plot. This is because the Router can actually take all sorts of configurations, depending on the specified constraints in terms which endpoints can be routed to, the minimum acceptable performance level for a given metric, etc. As a result, a virtually infinite number of routers can be constructed by changing these parameters, allowing you to customize the routing depending on your requirements!
Runtime routing#
When querying endpoints, other metrics beyond quality can be critical depending on the use-case. For e.g, cost may be important when prototyping an application, latency when building a bot where responsiveness is key, or output tokens per second if we want to generate responses as fast as possible.
However, endpoint providers are inherently transient (You can read more about this here), which means they are affected by factors like traffic, available devices, changes in the software or hardware stack, and so on.
Ultimately, this results in a landscape where it’s usually not possible to conclude that one provider is the best. Let’s take a look at this graph from our benchmarks.
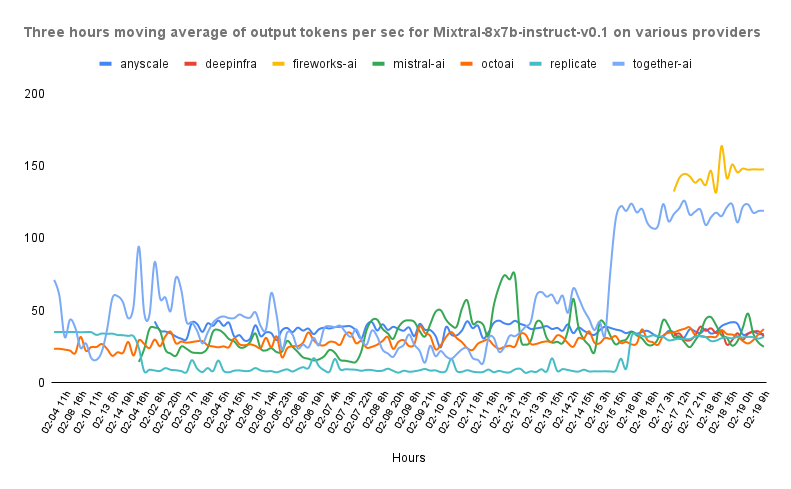
In this image we can see the output tokens per second of different providers hosting a Mixtral-8x7b public endpoint. We can see how depending on the time of the day, the best provider changes.
With runtime routing, your requests are automatically redirected to the provider outperforming the other services at that very moment. This ensures the best possible value for a given metric across endpoints.

Round Up#
You are now familiar with routing. Next, you can learn to use the router, or build your custom router.